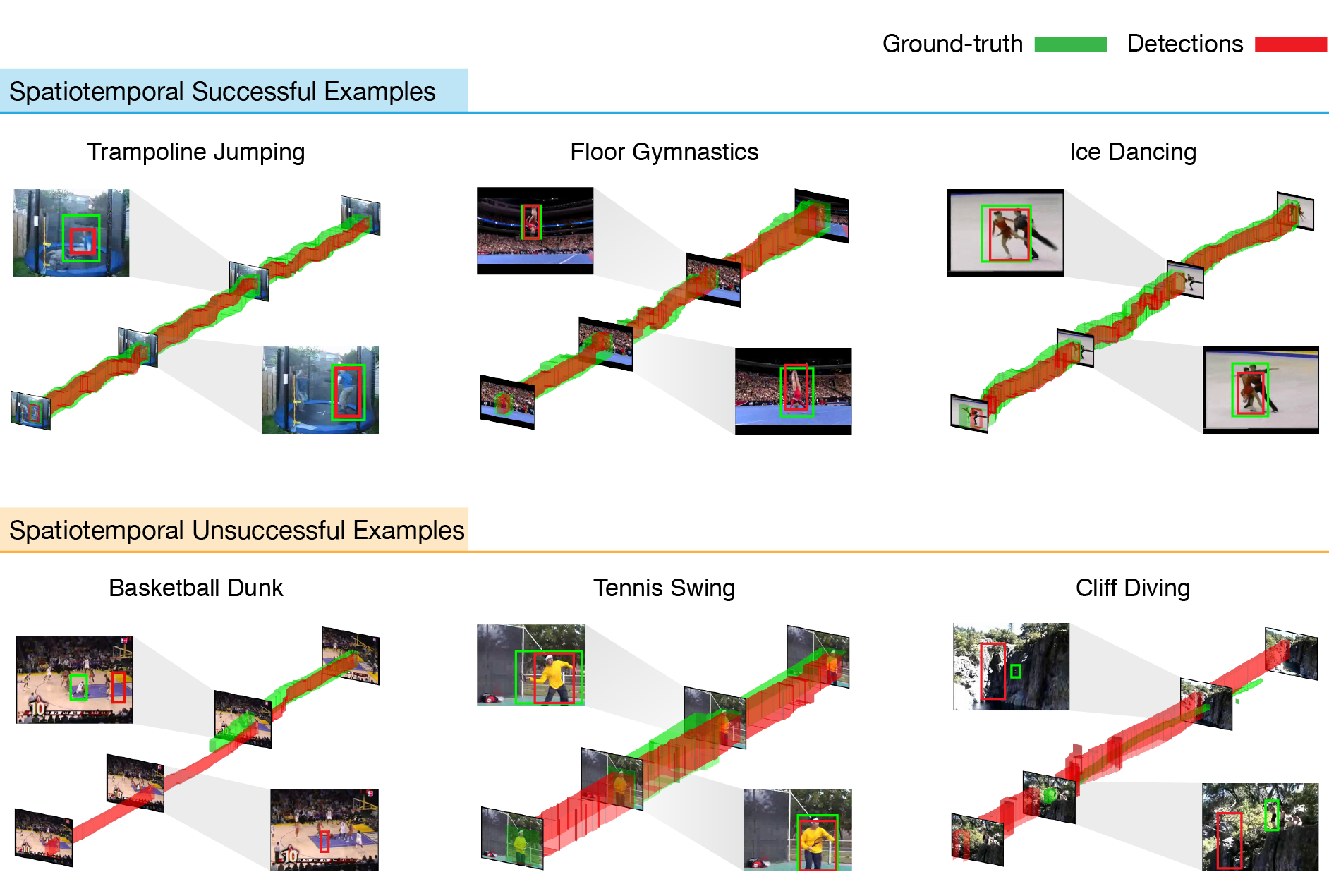
Qualitative Results
These are some of the detections of our algorithm on consumer videos.
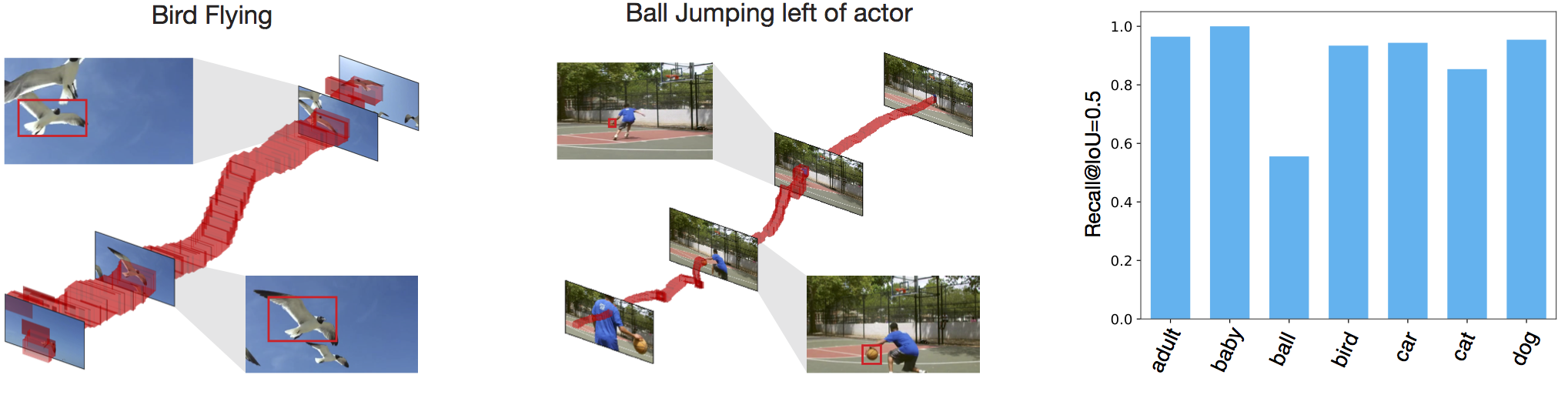
Actor proposals on non-human actors
Our approach is able to generate non-human actors proposals on the A2D dataset. On the left and center, qualitative visualizations of action proposals are shownfor two non-human actors,Bird and Ball. Recalls at IoU=0.5 for all 8 actor classes are shown on the right side. The recalls are consistently high for all the classes except for Ball, which is understandable due to its common shape and small size, which invite many occlusions